Jobs not starting
Postmortem
Incident Report: 2023-03-14 - Delays Starting Jobs
Summary:
On March 14, 2023, at approximately 18:00 UTC, all customers' pipelines began to experience delays in starting, ultimately resulting in jobs not running. This incident lasted until approximately 01:27 UTC. In short, an ongoing Kubernetes upgrade created a version mismatch between kubelet and kubeproxy, leading to widespread networking failures in our main production cluster. The remediation efforts for this incident also led to two incidents caused by errors in our queuing system using RabbitMQ queues and nodes, from 02:50 to 05:14 UTC, where all customer pipelines experienced delays, and from 09:50 to 13:15 UTC where GitHub checks were delayed by as much as 30 minutes.
The original status page updates can be found here: Jobs not starting, Jobs not starting cont'd and GitHub Checks are delayed.
We want to thank our customers for your patience and understanding as we worked to resolve this incident.
What Happened
In the week prior to this event, our infrastructure team had been slowly carrying out an upgrade of our main production Kubernetes cluster. On March 13th, 2023, after updating a few components, some services started reporting missing metrics. We proceeded to revert the changes and things seemingly recovered as the metrics came back. After reviewing and adjusting the plan to limit the blast radius, at approximately 17:40 UTC on March 14th, we attempted a different approach to upgrading these components. At 18:00 UTC, we started seeing an increase in communication errors on one of our services. As more engineers and teams joined the incident call, we could see that we were facing a much more widespread impact throughout multiple services and on all functionalities of the application. As the delays in job processing continued to climb and as our job queues started backing up across multiple services, we restarted a few services in an attempt to mitigate some of the symptoms we were seeing. Soon, it became clear that the issues were stemming from failures in service-to-service communication, and within an hour, the initial degraded state of the application became a significant incident.
After continued investigation, digging through logs, metrics, and attempts to connect to services using internal Kubernetes domain names directly from the pods, we suspected that the networking issues leading to communication failures were either due to kube-proxy, core-dns or node-local-dns-cache. This was difficult to verify, as all of those workloads appeared to be healthy.
Between 20:00 and 21:00 UTC, we decided to restart node-local-dns-cache and core-dns, which caused DNS resolution to fail completely. The team was starting to hone in on kube-proxy as the main culprit and the restart of one of the nodes gave us more confidence as we noticed that requests related to that node were going through. At this point, we continued on the restart path and restarted every node. By 23:00, all the nodes were rolled out and we had started seeing recovery except for those jobs using contexts or machine executor. We then restarted a separate pool of dependencies and by 01:15 UTC, March 15th, all jobs were executing correctly.
During recovery, we identified that were missing logging for RabbitMQ, so to complete our mitigation efforts, we rolled the rest of our infrastructure. At approximately 02:50 UTC RabbitMQ connection errors led to another episode of delayed jobs that we were able to mitigate by 03:35 UTC. This second incident was fully resolved by 05:14 UTC.
A subsequent restart of the RabbitMQ nodes was carried out to fix a few corrupted queues that caused another degradation in GitHub checks at 09:50 UTC, March 15th. We mitigated the issue by 11:08 UTC and after a long period of monitoring the situation, the incident was fully resolved at 13:15 UTC.
Post Incident Contributing Events Analysis:
Due to the broad impact of the networking issues, a complete restart of the cluster was ultimately needed to mitigate this issue. At the time of mitigation, it was evident that something in our Kubernetes upgrade process was responsible for this networking failure and further analysis was needed to see what we missed. Upon review, we identified that at the onset of the incident, kube-proxy, a network proxy running on every node in the Kubernetes cluster had a spike of "Sync failed" errors.
"Failed to execute iptables-restore" err="exit status 1 (iptables-restore: line 8022 failed\n)"
"Sync failed" retryingTime="30s"
To understand what’s happening here, it’s important to understand the role of Kube-proxy in a cluster. Pods (smallest deployable units) in a cluster have a temporary life cycle. They are ephemeral by nature and are terminated or created as required. Usually, each pod is running a single instance of an application. They are able to reach each other using unique IP addresses that are assigned to them. These IP addresses can change without warning in response to events such as scaling or failures. A set of pods in a cluster are load-balanced by a Service object. Services are also assigned a virtual IP address and leverage an Endpoints object to keep track of what pods are available at any given time. Kube-proxy, as noted above, runs on each node of the cluster and watches the Service and Endpoints objects. When changes occur in these objects, updates the routing rules on the host nodes are updated using iptables (the default execution mode for kube-proxy) a Linux firewall utility that allows or blocks traffic based on defined rules and policies. In a nutshell, kube-proxy consumes these Endpoints objects and modifies the local node's iptables to implement a local load balancer for each Service's virtual IP. As pods are created or destroyed in response to events, kube-proxy reconciles the rulesets on the node against the available Endpoints.
In the course of its normal operation kube-proxy performs a read/modify/write operation in the Proxier.syncProxyRules() method. This method uses the system iptables-save and iptables-restore commands to read in the state, create new rules, and write the state back out. Between the two Kubernetes versions we were working with, the handling and format of kube-proxy's rulesets changed.
What we did not notice was when we rolled back the kube-proxy version on March 13th, a very small amount of Sync-failure errors started showing up in our logs as visible in the graph below.
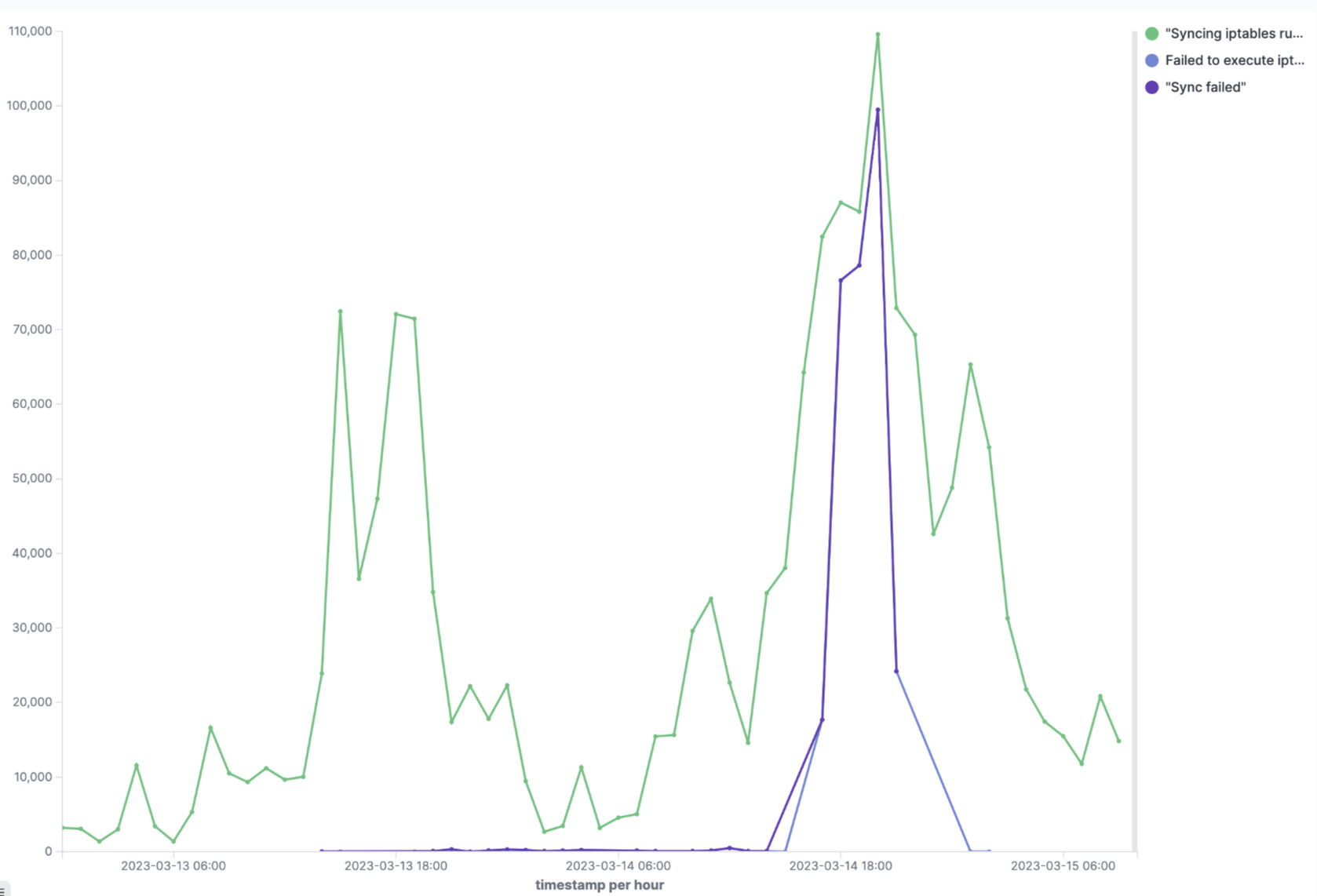 As we rolled out more pods and existing
As we rolled out more pods and existing Endpoints objects changed in response to these events, kube-proxyattempted to sync and reconcile the iptables on the nodes and failed to do so. These errors increased as more changes to pods and services were introduced during the upgrade process and on March 14th, as we resumed the upgrade, a spike in sync errors left the iptables on multiple nodes in a very corrupted state.
 When we restarted the node, a fresh
When we restarted the node, a fresh iptable ruleset was created and as we completed a full restart of the clusters, the sync errors disappeared restoring networking within the cluster.
Future Prevention and Process Improvement:
As we analyzed the contributing factors, we realized that there was not one single trigger that led to this incident. Due to the foundational nature of networking, Kubernetes upgrade are inherently risky and our risk mitigation strategies were not effective in the scenario where an interaction of multiple events ultimately triggered this incident. Our infrastructure engineering team is enhancing our Kubernetes upgrade process in order to significantly limit this risk model for future upgrades. In addition, we have enhanced observability with additional metrics and alerts specifically related to the sync errors being thrown by kube-proxy during the incident.
Additionally, we are evaluating strategies to improve the resilience of our RabbitMQ infrastructure.
Once again, we thank you for your patience as we worked to mitigate the incident and perform a thorough analysis of the events that caused this incident. Our goal remains to continue to improve the resilience and reliability of our application.
Resolved
Monitoring
Update
Update
Docker jobs with contexts are starting to run successfully. We will continue to monitor for further issues with Contexts.
We are still working to add capacity for machine jobs.